Dataset Design for Large Language Models
CS 525: Training Data for AI
Vaishaal Shankar
Today's Outline
- The Data Problem: Scaling laws and the hunger for tokens
- Methodology: How we measure dataset quality
- Building DCLM-Baseline:
- Text extraction & heuristic filtering
- Deduplication (MinHash & Bloom Filters)
- Model-based filtering (fastText)
- Decontamination
- Results
- What is "High Quality"? Can humans tell?
- Discussion: Limitations and open questions
Part 1: The Data Problem
Why LLMs are hungry for data
Switching gears from image datasets to text datasets & language models
Quick Recap: What is a Language Model?
A language model learns to predict the next token given the previous tokens:
loss = xent(model(seq[:-1]), seq[1:])
What are Tokens?
Tokens are the atomic units the model reads — subword pieces, not full words:
- Typical vocabulary: ~32K-100K tokens (BPE or SentencePiece)
- Common words = 1 token, rare words get split into pieces
- ~1 token ≈ 0.75 words on average in English
Scaling Laws
Loss decreases as a power law (Kaplan et al. 2020):
- N — model parameters
- D — training tokens
- E — irreducible entropy
- FLOPs ≈ 6ND (compute budget)
Chinchilla Scaling Laws
Hoffmann et al. (2022) trained 400+ models from 70M to 16B parameters:
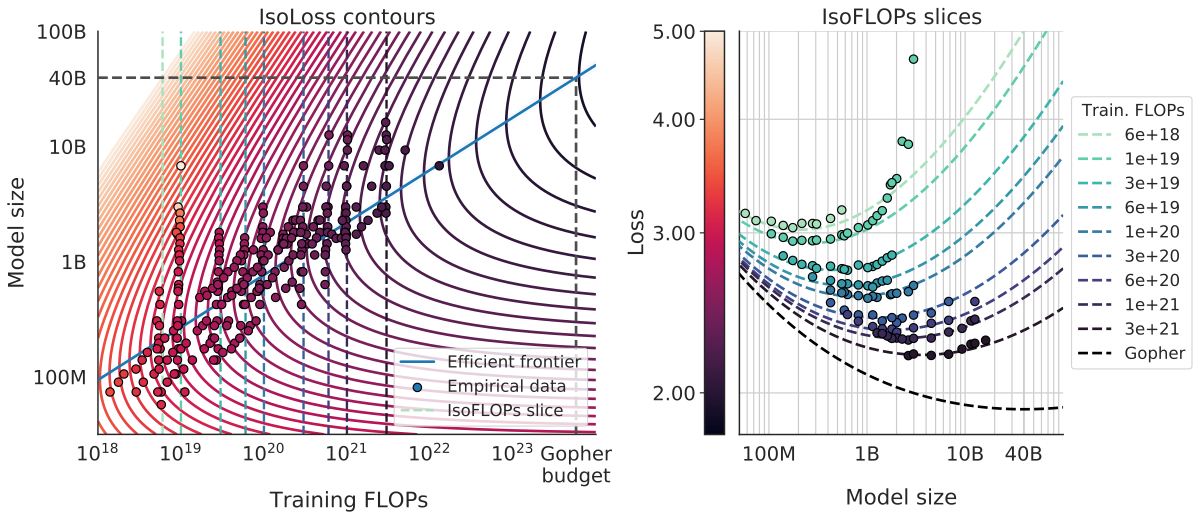
The Key Finding
For every doubling of model size, you should also double the training tokens:
| Model | Parameters | Training Tokens | Tokens/Param |
|---|---|---|---|
| GPT-3 | 175B | 300B | 1.7 |
| Gopher | 280B | 300B | 1.1 |
| MT-NLG | 530B | 270B | 0.5 |
| Chinchilla | 70B | 1.4T | 20 |
The Hidden Assumption
Scaling laws assume infinite high-quality IID data. But quality degrades as you scale:
- 1B → 100B tokens (GPT-1 → GPT-3 era): relatively easy to curate
- 100B → 1T tokens: manageable with careful filtering
- 1T → 10T tokens (GPT-4 era): hard, need aggressive filtering
- 10T+ tokens: very hard, scraping the bottom of the barrel
Modern Models are "Overtrained"
Most open-source models today train far beyond Chinchilla-optimal:
| Model | Parameters | Chinchilla Optimal | Actual Tokens | Overtraining Factor |
|---|---|---|---|---|
| Llama 2 7B | 7B | ~140B | 2T | 14× |
| Mistral 7B | 7B | ~140B | ~8T (est.) | ~57× |
| Llama 3 8B | 8B | ~160B | 15T | 94× |
| Qwen 2.5 7B | 7.6B | ~150B | 18T | 120× |
Chinchilla optimal ≈ 20 tokens per parameter
The Overtraining Trade-off
Why train beyond Chinchilla-optimal?
Benefits
- Smaller model = cheaper inference
- Fits on fewer GPUs
- Faster response time
- Performance still improves (log-linear)
Costs
- Harder to maintain data quality at scale
- Harsher diminishing returns
The Undertraining Problem
What about models trained with less data than Chinchilla-optimal? (GPT-3 era)
Benefits
- Need less training data
- Easier to curate quality
Costs
- Much larger model needed
- Inference is very expensive
- Requires more GPUs to serve
- Same harsh diminishing returns!
The Problem
LLMs convert training data into capability. More data generally means better models.
- But not all data is equal — quality matters enormously
- The internet has hundreds of trillions of tokens, but most is low-quality
- Hand-curating 1B tokens doesn't scale to trillions
- We need to maintain quality even as we 10× or 100× the data
Experimental Methodology
How do we measure dataset quality?
We use the methodology from DataComp for Language Models (DCLM).
There may be better datasets now, but the methodology for evaluating datasets remains sound.
The Evaluation Protocol
To compare datasets, we need to isolate the effect of the data:
- Fix the model: Same architecture (decoder-only Transformer) at each scale
- Fix the training: Same hyperparameters, same number of tokens
- Vary only the data: Train on different filtered datasets
- Evaluate: Test on 53 downstream tasks
- Compare: Better data → higher scores
Example Task: MMLU
MMLU (Massive Multitask Language Understanding) — 57 subjects, 15,908 questions
Question (World History):
Which of the following is the longest combatant nation in World War I?
(A) Japan (B) USA (C) Ottoman Empire (D) Germany
Answer: (D)
Tests factual knowledge across STEM, humanities, social sciences, law, medicine...
Example Task: HellaSwag
HellaSwag — Commonsense reasoning about everyday situations (70K questions)
Context:
A woman is outside with a bucket and a dog. The dog is running around trying to avoid a bath. She...
(A) rinses the bucket off with water from the hose.
(B) uses a hose to blow water into the dog's mouth.
(C) chases the dog around the yard with the bucket.
(D) gets the dog wet, then lathers it with soap.
Answer: (D)
Humans score ~95%, models must understand physical world & common activities
Example Task: WinoGrande
WinoGrande — Pronoun resolution requiring commonsense (44K problems)
Sentence:
The trophy doesn't fit into the brown suitcase because it is too [large/small].
If "large" → "it" refers to the trophy
If "small" → "it" refers to the suitcase
Requires understanding relative sizes, physical constraints, world knowledge
Our Evaluation Suite: 53 Tasks
We group tasks into two aggregates:
CORE (22 tasks)
- Tasks that give stable signal even at small scales (1B params)
- HellaSwag, ARC-Easy, ARC-Challenge
- PIQA, WinoGrande, BoolQ
- COPA, LAMBADA, OpenBookQA
- Selected BigBench tasks
EXTENDED (53 tasks)
- All CORE tasks plus:
- MMLU (0-shot and 5-shot)
- GSM8K (math word problems)
- TriviaQA, SQuAD, CoQA
- LogiQA, GPQA, and more
Why This Methodology?
- Controlled comparison: Only the data changes, everything else is fixed
- Reproducible: Same code, same hyperparameters, same evaluation
- Multi-scale: We test at multiple scales to validate findings
Multi-Scale Evaluation
We evaluate at 4 compute scales:
| Scale | Parameters | Tokens | ~GPU Hours |
|---|---|---|---|
| XS | 412M | 8B | ~50 |
| S | 1B | 29B | ~500 |
| M | 3B | 56B | ~2,500 |
| L | 7B | 138B | ~10,000 |
Rankings Transfer Across Scales
Similar to DataComp (images), we see strong correlation across scales for text datasets:
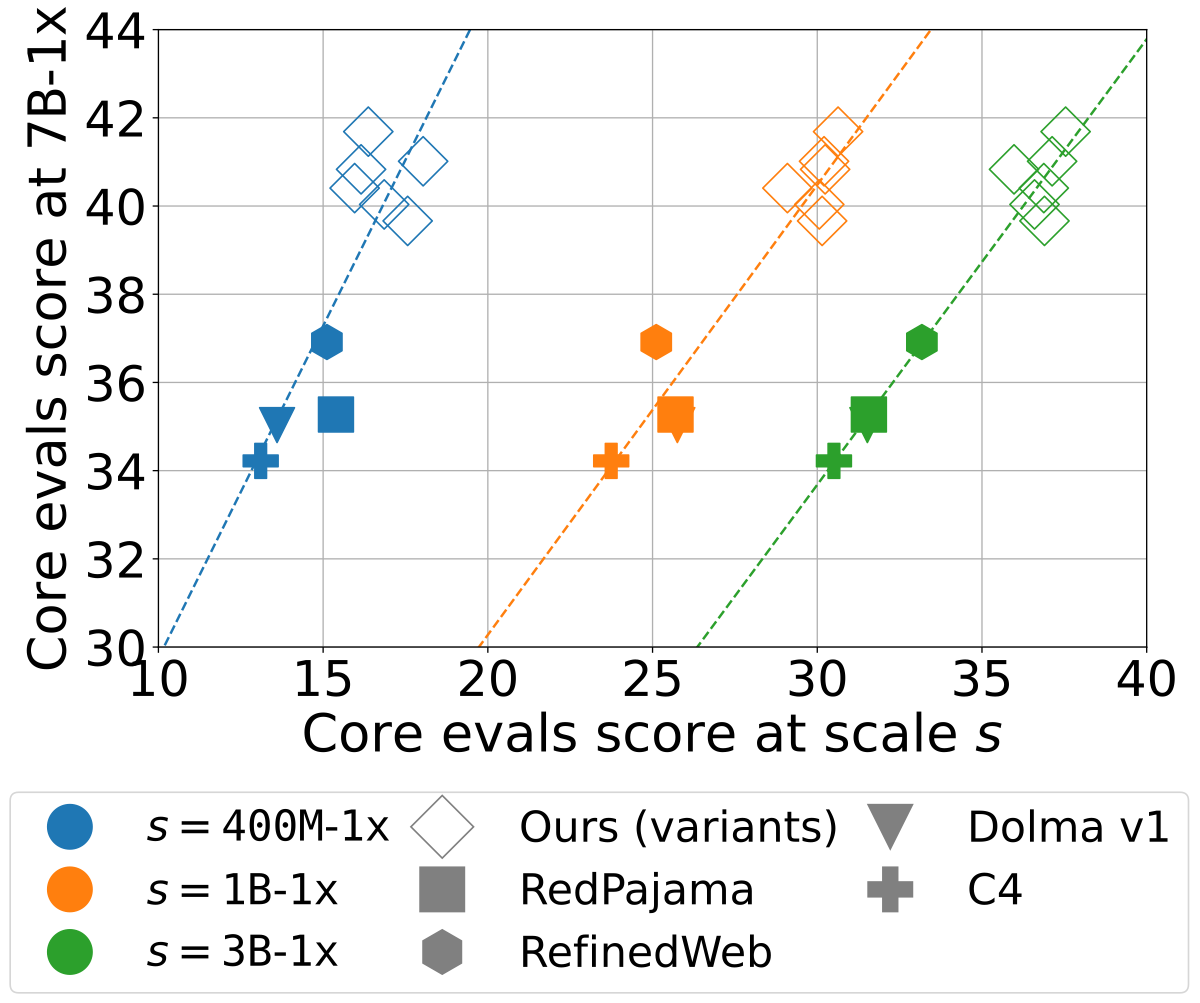
Part 2: Building DCLM-Baseline
From 240T raw tokens to 3.8T high-quality tokens
Pipeline Overview
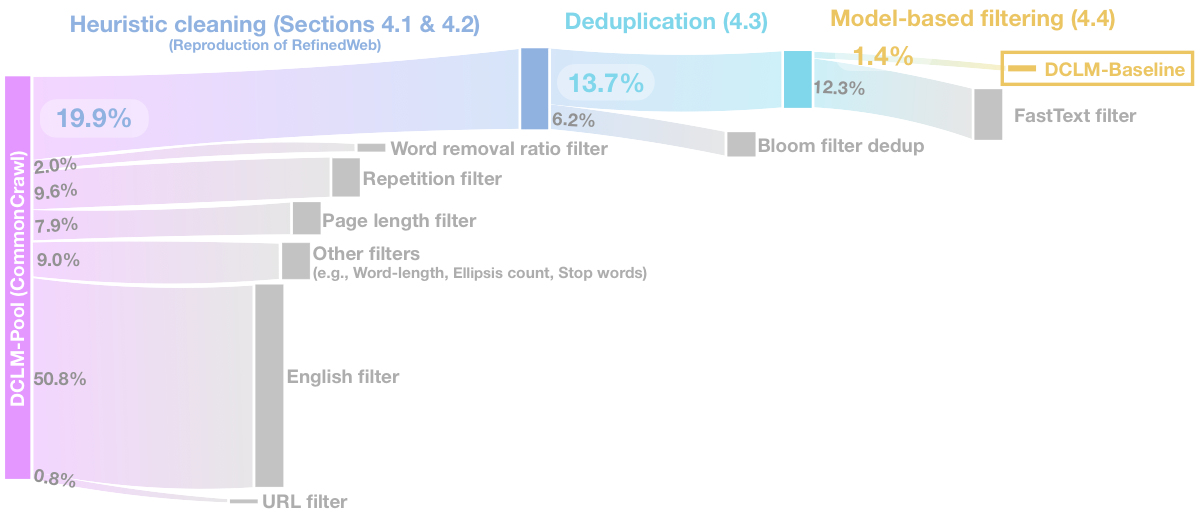
Pipeline Steps
(240T tokens)
(resiliparse)
(RefinedWeb)
→
(Bloom Filter)
(fastText)
(3.8T tokens)
~1.4% of original documents retained
Step 1: Text Extraction
Common Crawl provides raw HTML. How do we extract text?
| Method | Description | CORE | Speed |
|---|---|---|---|
| WET files | Pre-extracted by Common Crawl | 20.7 | - |
| trafilatura | Strict extraction, removes boilerplate | 24.5 | 1x |
| resiliparse | Fast, good quality extraction | 24.1 | 8x |
WET vs resiliparse: Example
WET (Common Crawl default)
Site Index The New York Times Site Index Navigation News World U.S. Politics N.Y. Business ... Skip to content Skip to navigation Subscribe Now Log In ... HERE is a sampling of some of the better antiques... ... © 2019 The New York Times Company Terms of Service Terms of Sale Site Map Help
resiliparse
This is a digitized version of an article from The Times's print archive, before the start of online publication in 1996. May 10, 1990, Page 00006 The New York Times Archives HERE is a sampling of some of the better antiques and flea markets around the United States. Two or Three Times a Year BRIMFIELD Route 20, Brimfield, Mass. 01010; 413-245-3436...
resiliparse removes navigation, footers, boilerplate → cleaner content
Baseline: Existing Datasets
We found RefinedWeb outperformed all other open-source datasets (of the time):
| Dataset | Sources | CORE |
|---|---|---|
| C4 | Common Crawl + heuristics | 34.2 |
| Dolma-V1 | Common Crawl + Wiki + Books + ... | 35.0 |
| RedPajama | Common Crawl + Wiki + Books + ... | 35.3 |
| RefinedWeb | Common Crawl only | 36.9 |
Step 2: Heuristic Filtering
We reproduce the filters from RefinedWeb (Penedo et al., 2023) — a key paper we build on:
Document-level filters
- Language: Keep English only (fastText)
- URL blocklist: Remove adult/malicious domains
- Length: Min/max document length
- Word count: Reasonable word count
Content quality filters
- Repetition: Repeated n-grams, lines, paragraphs
- Stop words: Minimum fraction of stop words
- Ellipsis: Max ellipsis count
- Boilerplate ratio: Words removed vs kept
| Filter | Example removed | % Removed |
|---|---|---|
| Non-English | "Bienvenue sur notre site web..." | ~55% |
| Too short / too long | "Click here | Home | About" | ~10% |
| Repetition | "Buy now! Buy now! Buy now!..." | ~8% |
| Low stop-word ratio | "img_2847.jpg img_2848.jpg img_2849.jpg" | ~5% |
Combined, these heuristics remove ~80% of documents
Step 3: Deduplication
Removing duplicate and near-duplicate content
Why Deduplicate?
- Reduce memorization: Models can memorize repeated content verbatim
- Increase diversity: More unique examples per training token
- Remove boilerplate: Headers, footers, navigation repeated across pages
Can We Study Duplicates via Naive Subsampling?
A subsample may preserve quality distribution, but duplication behavior is more complex.
Deduplication Approaches
| Method | Granularity | Type | Key Idea |
|---|---|---|---|
| Exact hash | Document | Exact | Hash entire document |
| MinHash + LSH | Document | Fuzzy | Approximate Jaccard similarity |
| Suffix Array | Substring | Exact | Find repeated substrings |
| Bloom Filter (BFF) | Paragraph + Doc | Exact/Fuzzy | N-gram membership |
Prior work (GPT-3, RefinedWeb) used MinHash + Suffix Array
MinHash: The Idea
Goal: Efficiently estimate Jaccard similarity between documents
where A, B are sets of n-grams (shingles) from two documents
MinHash: Visual Example
More hash functions → better estimate. Typical: 100-1000 hash functions.
MinHash Algorithm
- Shingling: Convert each document to a set of n-grams (typically n=5)
- MinHashing: For k hash functions h₁...hₖ:
- Compute signature: sig(D) = [min(h₁(D)), min(h₂(D)), ..., min(hₖ(D))]
- LSH Banding: Reshape signature into b bands of r rows each
- Documents are candidates if they match in ANY band
- Candidate verification: Check actual Jaccard for candidates
Total hashes k = b × r. Trade-off: more hashes = more accurate but slower
MinHash: LSH Banding
Reshape the signature vector into a b × r matrix. Match if ANY row is identical:
k = b × r total hash functions. More bands b → catches more duplicates. More rows r → fewer false positives.
MinHash: Collision Probability
Why does this work? The probability of a match depends on the Jaccard similarity s:
- One hash match: P = s
- All r hashes in a band match: P = sr
- A band does NOT match: P = 1 − sr
- NO band matches: P = (1 − sr)b
- At least one band matches:
This creates an S-curve: low similarity → ~0% match, high similarity → ~100% match
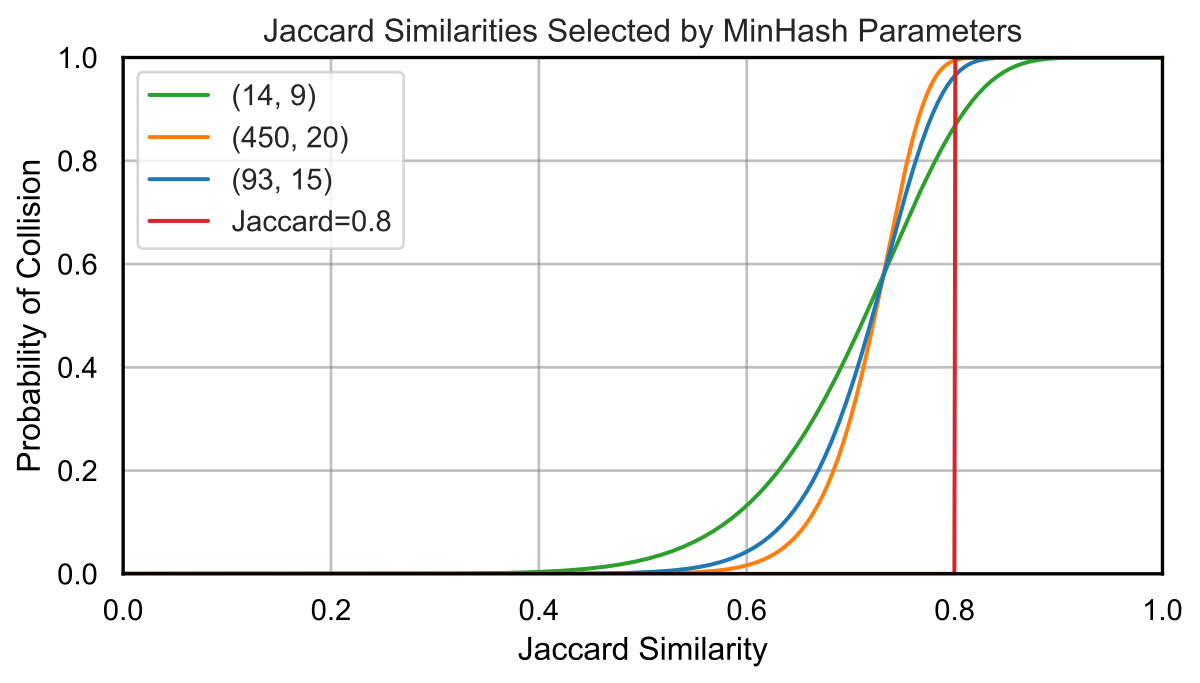
MinHash: Our Hyperparameters
| Setting | Value |
|---|---|
| N-gram size | 5 |
| Target Jaccard threshold | 0.8 |
| Bands (b) | 93 |
| Rows per band (r) | 15 |
| Total hashes (k = b × r) | 1,395 |
| Hash family | \( h(x) = (ax + b) \bmod p \) |
Each of the 1,395 hashes uses different random (a, b) values.
MinHash: Limitations
- Expensive at scale: 9000 permutations × billions of documents
- Document-level only: Can't remove duplicate paragraphs within otherwise unique documents
- Memory intensive: Need to compare all document pairs (or use LSH carefully)
- Sharding issues: Duplicates across shards not detected
Suffix Arrays (Intra-document dedup)
Find and remove repeated substrings across the corpus
- Concatenate all documents into one giant string
- Build suffix array (sorted list of all suffixes)
- Scan for repeated prefixes ≥ 50 tokens
- Remove all but one occurrence
Bloom Filters: The Idea
Problem: Check if an n-gram has been seen before (in a set of billions)
Solution: A bit array + multiple hash functions
Insert(x):
- Compute k hash functions: h₁(x), ..., hₖ(x)
- Set bits at those positions to 1
Query(x):
- Compute same k hashes
- ALL bits = 1 → probably in set
- ANY bit = 0 → definitely not in set
Bloom Filters: Visual Example
Our Approach: Paragraph + Document Dedup
We extend Bloom filters to work at both paragraph and document level:
- Split into paragraphs (by newline)
- For each paragraph with ≥ min_ngram_size tokens:
- Extract all n-grams of size max_ngram_size
- Check each n-gram against Bloom filter
- If >threshold fraction already seen → remove paragraph
- Otherwise, add n-grams to Bloom filter
- If >threshold of document n-grams seen → remove document
Bloom Filter Hyperparameters
| Parameter | Value | Reasoning |
|---|---|---|
| min_ngram_size | 13 | Avoid removing short list items (recipes, MCQs) |
| max_ngram_size | 13 | Sufficient for uniqueness |
| threshold | 0.8 | Match Jaccard target from MinHash |
| false_positive_rate | 0.01 | Hoeffding bound shows this is safe |
Comparing Deduplication Methods
We compare different dedup strategies on the same data (1B scale):
| Method | Tokens Left | Removed | Eval Score | Δ |
|---|---|---|---|---|
| No dedup | 76B | 0% | 24.7 | - |
| Exact hash only | 66B | 13% | 26.0 | +1.3 |
| MinHash only | 62B | 18% | 25.6 | +0.9 |
| Suffix Array only | 51B | 33% | 26.6 | +1.9 |
| Bloom Filter (ours) | 56B | 26% | 26.8 | +2.1 |
| All three combined | 45B | 41% | 26.8 | +2.1 |
Bloom filter alone matches the full combined pipeline!
Results at Larger Scale (7B model)
| Method | min_ngram | Shards | MMLU | Aggregate | Tokens |
|---|---|---|---|---|---|
| Bloom Filter | 5 | 32 | 32.5 | 44.5 | 3.9T |
| Bloom Filter | 13 | 10 | 44.3 | 45.3 | 3.8T |
| Bloom Filter | 20 | 10 | 43.6 | 45.8 | 3.9T |
| MinHash + Suffix Array | N/A | 16 | 44.4 | 45.5 | 3.2T |
Sharding: A Practical Necessity
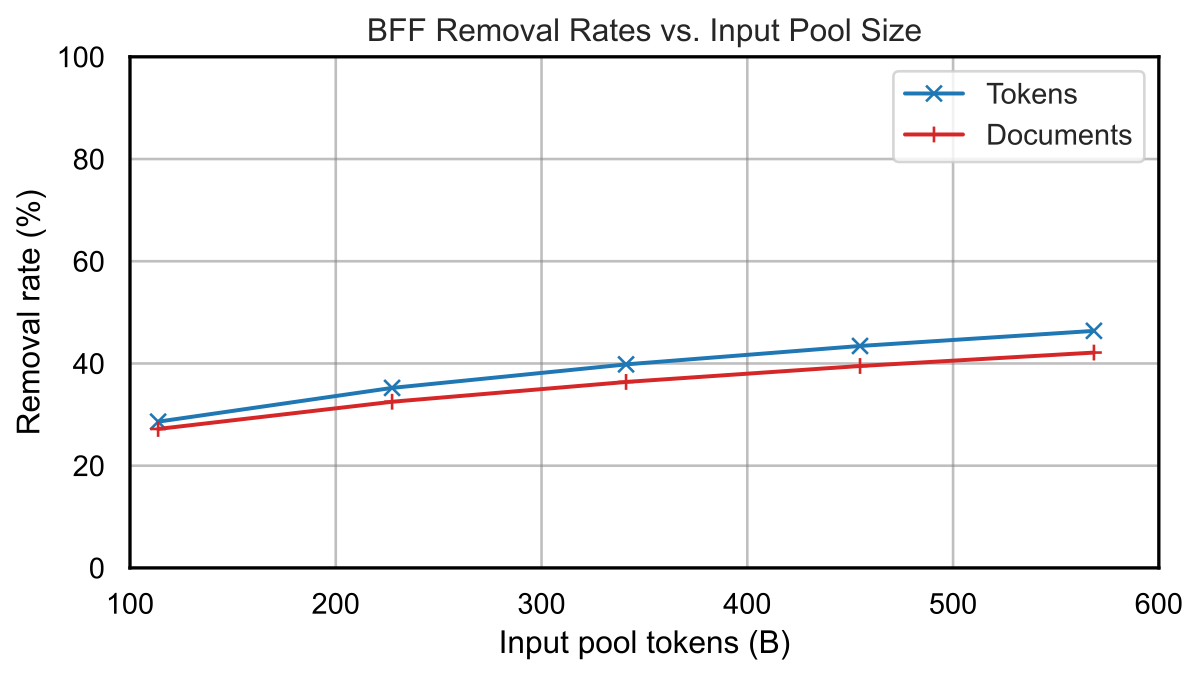
- More shards = more parallelizable, higher token yield
- Fewer shards = more thorough dedup, lower token yield
- DCLM-BASELINE: 100-way sharding (~700GB per shard)
The Sharding Tradeoff
Sharding: Splitting the corpus into independent chunks for parallel processing
The Sharding Caveat
If doc A appears in shard 1 and shard 50, both copies survive.
Global dedup (catches all duplicates) → requires global state, doesn't parallelize
Sharded dedup (misses cross-shard duplicates) → parallelizes perfectly
We hoped cross-shard duplicates would be rare...
Deduplication Summary
- MinHash: Good for fuzzy document-level dedup, but computationally expensive
- Suffix Array: Good for exact substring removal, but requires loading entire corpus in RAM
- Bloom Filter: Works at paragraph + document level, scales well, fast
Step 4: Model-Based Filtering
Using classifiers to identify high-quality documents
The Idea: Train a Quality Classifier
Heuristics and deduplication help, but can we do better with machine learning?
- Positive examples: Text from a known high-quality source
- Negative examples: Random sample of web-crawled text
- At inference: Score each document, keep top-k%
What is fastText?
fastText (Facebook, 2016) is a fast, shallow neural network for text classification:
Training the fastText Classifier
Training Data
- ~400K documents total
- 200K positive (high-quality reference)
- 200K negative (random web text)
Settings
- Features: unigrams + bigrams
- Embedding dimension: 100
- Training: ~minutes on CPU
- Score every document in the corpus (billions of docs)
- Rank by P(high quality)
- Keep top 10% (or other threshold)
The Key Question: What Reference Data?
The classifier needs positive examples. What should we use?
Traditional choices:
- Wikipedia
- Books
- Curated web (OpenWebText)
Our finding:
- Instruction-tuning data works much better!
- Q&A format, clear explanations
- Diverse topics
What is OpenHermes 2.5?
A dataset of ~1 million instruction-response pairs:
- Created by prompting GPT-4 and other LLMs with diverse instructions
- Covers coding, math, writing, reasoning, roleplay, etc.
- Originally made for instruction-tuning models
User: Explain quantum entanglement in simple terms.
Assistant: Quantum entanglement is when two particles become connected in such a way that measuring one instantly affects the other, no matter how far apart they are...
We also add ELI5 (Explain Like I'm 5) — a Reddit Q&A dataset with upvoted explanations.
Reference Data Makes a Huge Difference
| Positive Reference Data | Keep Top | CORE | MMLU |
|---|---|---|---|
| Wikipedia | 10% | 35.7 | 27.0 |
| OpenWebText2 | 10% | 34.7 | 25.0 |
| Wiki + Books + OpenWebText | 10% | 37.5 | 24.4 |
| OpenHermes 2.5 + ELI5 | 10% | 41.0 | 29.2 |
Why Does Instruction Data Work?
Honest answer: We don't really know!
Some hypotheses:
- Clear, explanatory writing style
- Question-answer structure matches evaluation format
- High information density, no boilerplate
- Diverse topic coverage
Threshold Matters
| Keep Top % | CORE | MMLU |
|---|---|---|
| 10% | 41.0 | 29.2 |
| 15% | 39.8 | 27.2 |
| 20% | 38.7 | 24.2 |
Comparing Quality Filtering Methods
We tried many approaches to identify high-quality documents:
| Method | Description | CORE |
|---|---|---|
| Heuristics only | RefinedWeb filters | 27.5 |
| PageRank top 20% | Keep well-linked pages | 26.1 |
| Perplexity filtering | Keep low-perplexity text | 29.0 |
| LLM-as-judge | Ask Mistral-7B if doc is useful | 28.6 |
| fastText classifier | Trained on instruction data | 30.2 |
Does This Hurt Instruction Tuning?
Concern: Using instruction data for filtering might "use up" the gains from instruction tuning later?
- After pretraining, models are typically fine-tuned on instruction data
- Does filtering with OpenHermes reduce the benefit of instruction tuning?
Step 5: Decontamination
Removing evaluation data from training
Why Decontaminate?
If evaluation examples appear in training data, benchmarks become meaningless.
- Problem: Web crawls may contain benchmark questions/answers
- Risk: Models memorize answers instead of learning to reason
- Solution: Remove documents that overlap with eval sets
Contamination Results
After running decontamination on DCLM-BASELINE:
< 0.01%
of documents removed due to contamination
- Contamination rate was very low
- Most benchmark data is not in Common Crawl (or filtered out earlier)
- fastText filtering may inadvertently help (benchmarks ≠ instruction-like)
Step 6: Results
How does DCLM-BASELINE perform?
Scaling to Trillion Tokens
For our final model, we combined DCLM-BASELINE with code and math data:
- Data mix: DCLM-BASELINE (3.8T) + StarCoder (code) + ProofPile2 (math)
- Model: 7B parameters, trained for 2.5T tokens
- Learning rate schedule: Two-phase cooldown with tighter filtering
- Context length: Extended from 2K to 8K tokens
Main Results (as of June 2024)
Compute Efficiency
64% MMLU
with 7B parameters, 2.6T tokens
Similar MMLU (64% vs 66%)
6.6× less compute
Similar MMLU (64% vs 63%)
Open data!
+6.6 pp on MMLU
40% less compute
Instruction Tuning Results
Does DCLM-BASELINE pretrained model instruction-tune well?
| Model | Pretrain Data | IFEval | GSM8K | MMLU | BBH |
|---|---|---|---|---|---|
| Mistral-7B-Instruct | Closed | 57.2 | 40.0 | 53.9 | 42.2 |
| Llama-2-7B-Chat | Closed | 42.5 | 23.3 | 48.0 | 35.6 |
| DCLM-7B-Instruct | Open (ours) | 59.3 | 51.2 | 63.2 | 45.1 |
Key Findings Summary
- Text extraction matters: resiliparse >> WET files (+3.4 CORE)
- Deduplication helps: +2.1 CORE points
- Model filtering is key: fastText with instruction data is best
- Mixing can hurt: When filtering is good, adding Wiki/Books hurts
- Small scales predict large: r > 0.95 between 1B and 7B
Part 3: What is "High Quality"?
Can humans identify good training data?
Let's Play a Game
I'll show you documents from our pipeline. Guess which stage they came from:
Pool
Raw Common Crawl text. No filtering. Mostly junk.
RefinedWeb
After heuristic filters. Better, but still noisy.
DCLM-BASELINE
After heuristic + ML filtering. Best eval performance.
Document #1: Which dataset?
My Photo
MY Resume
May 2013
Sun Mon Tue Wed Thu Fri Sat
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30 31
Become a Fan
Blog powered by TypePad
« how about a little Echo Park | Main | go check this out! »
April 22, 2011
TrackBack
TrackBack URL for this entry:
http://www.typepad.com/services/trackback/6a00e54ee675c6883301538e102cfc970b
Listed below are links to weblogs that reference Have a fantastic Easter break:
Comments
jill
thinking of you lately!!!!! enjoy your family today.
xox,
j.
Verify your Comment
Previewing your Comment
This is only a preview...
Pool, RefinedWeb, or DCLM-BASELINE?
Document #1: Answer
Pool (resiliparse extraction, pre-filtering)
Actual sample from DCLM-Pool — a blog sidebar:
- Calendar widget, navigation links
- TrackBack URLs, comment previews
- No substantive content
Heuristic filters remove this — too short, mostly boilerplate
Document #2: Which dataset?
[ style: dark classic gorilla ] Photo Gallery : photo No. 1 photo No. 2 photo No. 3 photo No. 4 photo No. 5 photo No. 6 photo No. 7 photo No. 8 photo No. 9 photo No. 10 photo No. 11 photo No. 12 photo No. 13 photo No. 14 photo No. 15 photo No. 16 photo No. 17 photo No. 18 photo No. 19 photo No. 20 photo No. 21 photo No. 22 photo No. 23 photo No. 24 photo No. 25 photo No. 26 photo No. 27 photo No. 28 photo No. 29 photo No. 30 photo No. 31 photo No. 32 photo No. 33 photo No. 34 photo No. 35 photo No. 36 photo No. 37 photo No. 38 photo No. 39 photo No. 40 photo No. 41 photo No. 42 photo No. 43 photo No. 44 photo No. 45 photo No. 46 photo No. 47 photo No. 48 photo No. 49 photo No. 50 photo No. 51 photo No. 52 photo No. 53 photo No. 54 photo No. 55 photo No. 56 photo No. 57 photo No. 58 photo No. 59 photo No. 60 photo No. 61 photo No. 62 photo No. 63 photo No. 64 photo No. 65 photo No. 66 photo No. 67 photo No. 68 photo No. 69 photo No. 70 photo No. 71 photo No. 72 photo No. 73 photo No. 74 photo No. 75 photo No. 76 photo No. 77 photo No. 78 photo No. 79 photo No. 80 photo No. 81 photo No. 82 photo No. 83 photo No. 84 photo No. 85 photo No. 86 photo No. 87 photo No. 88 photo No. 89...
Pool, RefinedWeb, or DCLM-BASELINE?
Document #2: Answer
Pool (resiliparse extraction, pre-filtering)
Photo gallery navigation page — actual sample from DCLM-Pool:
- Just a list of links: "photo No. 1, photo No. 2..."
- No actual content, just navigation
- Highly repetitive structure
Heuristic filters catch this: repetition filter removes it
Document #3: Which dataset?
Fishing Lures Product Image Item Name- Price Early Shurebite Frog Fishing Lure w/Box Nice early Shurebite Frog Fishing Lure. Lure comes with its original box and was made by Shurebite, Inc. Bronson, Michigan. Im guessing Lure is from the 1950s to early 60s. Lure itself appears to be in good condition. Some light wear to the wood top portion but Lure does not appear to have been used. The end of the Box lid does have a couple punctures in it and the top lid has in ink writing #250. Lure would make a fine addition to any Vintage Fishing collection. Buyer to pay shipping & insurance. Fishing Lure Panatella by South Bend Fishing Lure by South Bend a Panatella fishing lure. Red and white (now creamy) paint with tack eye. Three sets of hooks, silver propellor. The paint is crazed & stained in some areas. 3 3/4 inches wooden lure. The panatella minnow was made (1912-1942) Red white paint tack eye. Heddon 4in Dowagic Crab Wiggler Fishing Lure Heddon 4 in Dowagesic Crab Wiggler Fishing Lure. Patented 1916 wooden lure has seen some action. Original yellow paint has cracks in the paint & some dings...
Pool, RefinedWeb, or DCLM-BASELINE?
Document #3: Answer
RefinedWeb (Heuristic filters only)
Actual sample from DCLM-RefinedWeb. Passed heuristic filters.
But the ML classifier rejected it — not in DCLM-BASELINE.
We don't know exactly why.
Document #4: Which dataset?
Take the 2-minute tour × Here what happened with me today. TimeMachine asked me whether I want to set a backup disk, I've answered yes, but then, when I've realized that in order to backup anything TimeMachine will clean the disk, I've changed my mind and canceled everything. And my disk suddenly became read only. What I've tried before Googling: $ sudo chflags -R nouchg Elements/ $ sudo chmod -R a+w Elements/ But I've failed with both of this, getting "read-only file system" messages. What I've tried after Googling: 1. Open Disk Utilities 2. Click Repair Disk Permissions But this button is disabled, and I have no idea what exactly should be done to enable it. I have been using this disk for a quite a long time, and never had any permission issues with it. (Disk is formatted as NTFS, if that helps. Capacity is 2TB, of which 1.92TB are available.) I'd really appreciate if someone will give me a hint how this can be resolved. — Try booting from the Recovery HD and see if the button is still disabled.
Pool, RefinedWeb, or DCLM-BASELINE?
Document #4: Answer
DCLM-BASELINE (ML classifier approved)
Actual sample from DCLM-BASELINE (apple.stackexchange.com).
We don't know exactly why the classifier scored it highly — that's part of the mystery we're exploring.
Document #5: Which dataset?
Host: Zander Program Category: Music Frequency: Weekly Length: 2 Hours Terms: Barter Delivery Method: Internet "Zander's knowledge of music and his straight-forward approach has struck a huge interest among our listeners. The Rockin' 80's is EXACTLY what we've been looking for!" - Terry West, WQLA The Rockin' 80's is the only 80's show with a mix of the best rock from the decade of excess plus "oh wow" tracks that add spice to the weekly line up. The two hour version of the show features rarities from the 80's "Lost and Found", an 80's "Two-Fer," spotlighting two contrasting songs from one band played back to back. |3733 Park East Drive • Room 222 • Cleveland, Ohio 44122 P: 216-831-3761 • F: 216-514-4699 |©2014 Envision Networks. All rights reserved.
Pool, RefinedWeb, or DCLM-BASELINE?
Document #5: Answer
RefinedWeb (Heuristic filters only)
This passed heuristic filters.
But the ML classifier rejected it — not in DCLM-BASELINE.
Interesting — it has some real content about the radio show. Why was it rejected? We don't really know.
Document #6: Which dataset?
Is it necessary to purchase a travel book or is it realistic that we can get similar information from other resources? Usually, most individuals have a major question on buying a travel book. So here are the pros and cons of purchasing one such book. Advantages of a Travel Book A travel book, which may be a paperback or e-book, comes in handy while traveling. Glancing through a travel book enables you to understand the custom and culture of a particular place in the world. - They Come In Handy — The travel guide comes in various forms such as, e-books, paperbacks and the file formats. You can have easy access to these books, which would assist you with all details compatible to the region you are traveling to. - They Provide Enormous Information — Electronic or traditional travel guides provide you with answers to all types of questions such as how to learn some sayings that can be used in the place where you are traveling to? Disadvantages of Travel Book - The Price — The e-book and paperback travel guides are very expensive compared to the information obtained from travel websites. - Travel Books Make The Trip Less Natural — Traveling can be made more spontaneous by acquiring suggestions from locals than from travel books.
Pool, RefinedWeb, or DCLM-BASELINE?
Document #6: Answer
DCLM-BASELINE (ML classifier approved)
This document passed both heuristic filters and the ML classifier.
Why did the classifier like this one? We don't really know — and that's the point.
How Did You Do?
If you found it tricky, you're not alone...
- We asked 16 of our co-authors to label ~500 documents
- Three annotators per document, majority vote
- Average agreement: only 71%
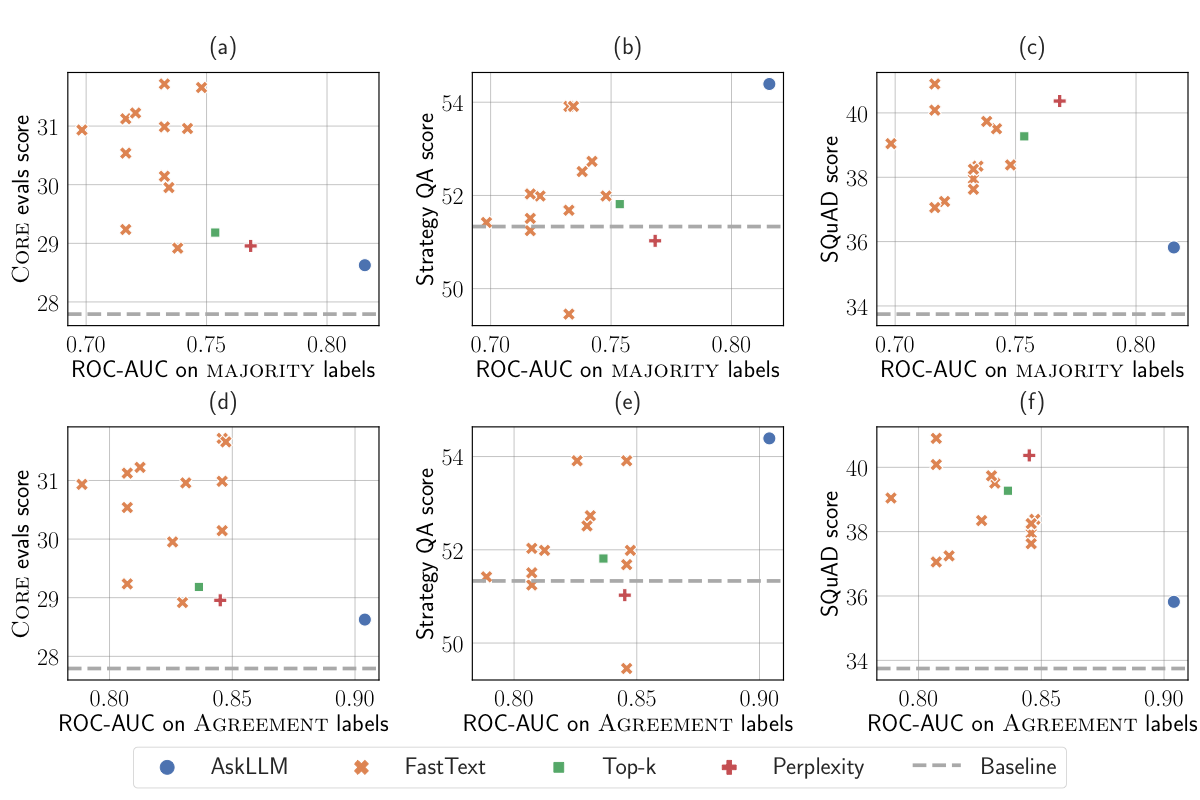
Human Judgment vs. Model Performance
The Surprising Result
| Method | Agreement with Humans | Downstream Score |
|---|---|---|
| AskLLM (Mistral-7B) | 82% | 28.6 |
| fastText (instruction data) | 73% | 30.2 |
The method that disagrees more with humans produces better training data!
Hypothesis: Humans may over-value "polished" content and under-value diversity.
So What IS High Quality?
We can't define it a priori. Instead:
- It's operational, not philosophical
- It depends on your downstream tasks
- Human intuition is not a reliable guide
- The only way to know is to train and evaluate
Part 4: Discussion
Limitations and open questions
Limitations
- Scale: Only tested up to 7B parameters
- Compute: Couldn't test all combinations
- Tokenizer: GPT-NeoX only (may affect multilingual/math)
- English-focused: Limited multilingual analysis
- Code/Math: Added StarCoder/ProofPile post-hoc
- Eval-focused: Optimized for MMLU, HellaSwag, etc. — may not generalize to all use cases
Post-Mortem: The Duplicate Problem
Why we chose Bloom filter deduplication:
- Efficiency: At the time, it was what we could run most efficiently
- MinHash is expensive: 9000 permutations × billions of docs
- Memory constraints: Suffix arrays require entire corpus in RAM
What Later Research Found
Two papers analyzed DCLM after publication:
arxiv.org/abs/2412.02595
- DCLM has ~80% near-duplicates
- Only ~1.0T unique tokens out of 3.8T
arxiv.org/abs/2503.07879
- 33-83% fuzzy duplicates (depending on pool)
- High-duplicate docs often higher quality!
We did not know this while writing the paper.
Lessons Learned
- Engineering constraints shape outcomes: We chose Bloom + sharding for efficiency, not optimality
- Measure what matters: We didn't measure global duplicate rate post-hoc
- Science is iterative: Later papers found issues we missed
Open Questions
- Why does instruction-formatted reference data work so well?
- What's the optimal threshold at even larger scales?
- Can we combine good filtering with smart mixing?
- How to extend to truly multilingual?
- Can we filter for safety/toxicity without hurting quality?
Summary
- Extract text with resiliparse
- Apply RefinedWeb heuristic filters
- Deduplicate with Bloom Filter (BFF), min_ngram=13
- Filter with fastText trained on OH-2.5 + ELI5, keep top 10%
Thank You!
Paper: arxiv.org/abs/2406.11794
Website: datacomp.ai/dclm
Code: github.com/mlfoundations/dclm
Questions?
Making of This Deck
Built with Claude Code in one session
(Yes, Claude made these slides too.)
The Setup
I gave Claude Code access to:
- The DCLM paper — full LaTeX source (
neurips_data_2024.tex), tables, and figures - The Chinchilla paper — LaTeX source and figures
- The DataComp paper — LaTeX source and figures
- Real data samples — downloaded live from Common Crawl during the session
- A Keynote deck from a previous version of this talk
The Process
- ~200+ back-and-forth messages over one session
- Started with a rough outline, then iterated slide by slide
- Claude Code wrote all HTML/SVG/CSS directly — no PowerPoint, no templates
- Real data examples fetched live from
data.commoncrawl.org - Figures converted from paper PDFs or drawn as SVG diagrams
- Multiple rounds of "make this bigger", "fix the overlap", "that's cut off"
What Worked Well
- Reading paper source directly: Claude extracted exact numbers from LaTeX tables
- SVG diagrams: Custom visuals (MinHash, Bloom filter, sharding, loss curves) without any design tool
- Rapid iteration: "Move this slide", "change the wording", "add a figure" — instant turnaround
- Data access: Downloaded and processed real JSONL samples from Common Crawl on the fly
What Needed Human Guidance
- Pedagogical structure: What order to present things, what to emphasize
- Intellectual honesty: "We don't know why instruction data works", "remove flashy words"
- Visual taste: "Labels overlap", "make it XKCD style", "too small"
- Domain knowledge: Post-mortem on duplicates, overtraining trade-offs, what's changed since the paper
The Stack
- Reveal.js — HTML presentation framework
- MathJax — LaTeX math rendering
- SVG — All custom diagrams drawn inline
- Claude Code — Wrote every line of HTML, CSS, SVG, and JS
- Netlify Drop — One drag-and-drop to deploy
index.html (~2800 lines) + figures/ (10 PNGs)
Backup Slides
Bloom Filter Math
Optimal number of hash functions:
Optimal size m for n elements:
For 1T tokens with ε=10⁻¹² → 6.5TB RAM
With ε=0.01 → much smaller, still safe due to threshold
False Positive Safety
Why ε=0.01 is safe with threshold T=0.8:
For a document with N n-grams where S are true duplicates:
With N=100, T=0.8, ε=0.01, S=60:
P(false duplicate) < 10⁻⁸
Global MinHash on Processed Datasets
| Dataset | Docs | Dedup Applied | Shards | MinHash Remaining Duplicates |
|---|---|---|---|---|
| DCLM-BASELINE | 3.2B | BFF | 100 | 85% |
| RefinedWeb (official) | 968M | MinHash+SA | 1 | 0% |
| RefinedWeb (ours) | 2.0B | MinHash+SA | 16 | 45% |
| Dolma V1 | 4.6B | Exact Bloom | 1 | 36% |
BFF and MinHash define "duplicate" differently. Remaining duplicates don't seem to hurt!
Training Hyperparameters
| Scale | Layers | Heads | d_model | LR | WD | Batch |
|---|---|---|---|---|---|---|
| 400M-1x | 24 | 8 | 1024 | 3e-3 | 0.033 | 512 |
| 1B-1x | 24 | 16 | 2048 | 3e-3 | 0.033 | 256 |
| 7B-1x/2x | 32 | 32 | 4096 | 2e-3 | 0.05 | 2048 |
Architecture: decoder-only Transformer, LayerNorm, qk-LayerNorm, SwiGLU, RoPE, seq_len=2048
Contamination Check
| Dataset | MMLU | HellaSwag |
|---|---|---|
| DCLM-BASELINE | 51.8 | 77.9 |
| DCLM-BASELINE (decontaminated) | 52.7 | 78.4 |
Removing overlapping examples does NOT decrease performance
Mixing Doesn't Help with Good Filtering
| CC Subset | Base CORE | + Wiki/Books/etc | Δ |
|---|---|---|---|
| C4 | 23.7 | 25.9 | +2.2 |
| RefinedWeb | 25.1 | 26.5 | +1.4 |
| DCLM-BASELINE | 31.1 | 29.9 | -1.2 |
When filtering is good, "high-quality" sources can actually hurt!
Small Models Also Benefit
| Model | Params | Tokens | CORE | MMLU |
|---|---|---|---|---|
| OLMo-1B | 1.2B | 3T | 29.7 | 26.0 |
| Gemma-2B | 2.5B | 3T | 43.3 | 40.8 |
| DCLM-BASELINE | 1.4B | 4.3T | 45.2 | 47.5 |